資料科學家或數據分析師的工作流程
動機
我們為何要當資料科學家
- 我們對於分析事物很有興趣
- 薪水: 當資料科學家的薪水不錯
不過也需要你是一個優秀的軟體工程師,通常具備的基本技能要熟悉 python 與 R ,加分項目包含前端 javascript, React, Vue 與 後端 Node.js, java 等以及容器化技術, CICD 等等。

工作流程
/images/Data+Science+Workflow+Image.jpg)
-
問題、目的 釐清與認識
如果大家有出來工作過就會發現一將無能累死三軍的現實, 可能你的長官需求亂變, 工作亂給, 什麼都不確定隨時在變, 但開發時間不會變卻是鐵律, 我們做數據科學家的部屬是要幫你的長官或更上級的長官解決問題, 只能耐心地循循善誘引導他們, 因為他們只有方向對於程序細節並不清楚。 現在舉個例子,我曾碰過一個要求”由叫聲去判斷是屬於哪種動物, 並確認是否保育動物”的專案任務。 以老闆的角度並不會多想技術細節, 認為沒什麼事情是做不出來的, 只要開發出來這功能就可以拿去賣錢, 他的腦中就只會天馬行空地關注商業噱頭而已。
下面我們回歸現實, 以資料科學家與工程師的角度來思考這個問題, 我們的收音設備可以收到多少分貝多清晰的聲音, 我們的設備會不會被其他聲音干擾, 麥克風是指向還是環繞? 你可能會想問這些考慮有關係嗎? 因為我們是要分辨叫聲去做分類, 所以我們所要收集的動物叫聲, 必須要考慮到那些目標動物的叫聲是老的還是小的, 以及雌雄間的異同, 不同地區或不同季節的叫聲是否會有差別等等問題, 我們設計的收音設備跟使用者實際使用的收音設備有差嗎, 是否需要加註使用者技術規範。 同時在工程上要考慮到模型的可擴展性, 可替換性, 我們是自己開發設備或是用別人的系統, 有網路需求嗎等等問題, 老闆都會以為我付你薪水這些問題都是你自己要去搞定的, 但是難道你會為了達成任務不計代價嗎? 有些工作會有許多雜事, 像是數據收集、數據清理等等, 可能都會把它壓在你的頭上, 他們理所當然覺得這是你研發工程師的份內之事, 所以一開始就要把問題與目的釐清, 讓上面知道每個階段所要花的時間與人力成本有多少, 還有市面上其他競爭產品有哪些, 目前開發出來的成品在市面上的優劣勢分析, 如果事前沒有做足完整規劃, 你就會嚐到長官與老闆奇思妙想的苦果, 你出來工作可能會發現一堆動嘴不動手的人,
整天只會批評叫別人做事自己卻兩手一攤, 但這些都不是我們首要關注的事, 如何增加自己的職場競爭力才是正確該做的事情。 -
資料的獲取
根據要分析的問題,我們先要收集數據,如果要做監督學習 supervise learning,我們還要清楚要什麼樣的紀錄,什麼樣的格式。
下面舉個例子: 掀背車/images/Three_body_styles_with_pillars_and_boxes.png)
/images/Honda.jpg)
假設你要出一個分類不同車子的模型,為了教會模型分辨車子的種類,先要找人在大馬路上,各地點拍了一堆影片,在標記車子類型之時,你會發現有很多模糊的地方,可能是車子的造型很特殊,或是他角度本來就很奇特,在決定要獲取什麼資料,與資料格式都是一個很麻煩的事,更嚴謹來說,現在會把資料也上版本,不光程式有版本,單元測試 unit test 有版本,連資料數據也要上版本。 -
數據整理 與 數據清理
我們所收到的原始數據通常都有很多問題,不見得都立即可用。例如 數據有缺失,格式不統一,或是沒有代表性等等。
這邊舉個例子說明為何格式不統一會有問題,假設我們要表示 “無” 這件事,有的人是用 0, null, 空格, 等等不同方式,這最常發生在有一些年頭的公司,任何公司都一定是從無到有,從小成長到大,一開始就沒有要做資料分析的規劃,只是留個紀錄備檔,但是當精準行銷,數據分析等概念興起的時候,老闆就會想要啟動新的經營模式,肖想公司爆發式的成長,讓停滯的業績有成倍的效果,但老闆或你的長官空有想法也不知道該怎麼做啊,但是公司最不缺的就是垃圾數據,有銷售數據,有業務留下的充滿個人風格的excel或是word紀錄文件,比較大的公司可能有建系統建資料庫,不過你也會發現公司雖有一堆資料庫一堆系統,但有些格式很複雜還對不上,或是要關聯很多次才會有可以拿來分析的有效數據,常見老闆給出的任務就是,我這裡有很多多數據,你不是做資料分析的嗎,拿去分析看看可以得出什麼結論,這時候如果你沒有比老闆更清晰的頭腦,你可能連該怎麼開始都不知道,更不要說去處理這一堆雜亂無章的數據。 -
資料分析 與 建立模型
我們要根據不同的任務去挑選不同的模型與參數,這一部分就是調模型、調參數的無限循環,也有人戲稱這階段叫煉丹。這部分我們會放在以後再做詳細介紹。 -
分析報告、可視化數據 或是 部署上線
做好模型以後,就是讓上面有可以說嘴的表現,長官與老闆完全不了解你花了多少努力, 那些模型是什麼他也都完全不懂,所以你要用可視化的工具, 讓完全不懂的人都可以頭頭是道講出來, 好像這是英明長官領導下的成果。
等老闆邀完功, 接著就該把你辛苦的成果上線部署給測試部門去測試, 再去回報之前還沒考慮的問題,例如只是把自己的叫聲拿變聲器改一改就去測試哪種動物, 或是各種Bug等等, 等你修到都沒問題時就可以正式上線了。

人工智慧 Artificial Intelligence (AI)
我們來談談人工智慧的分類
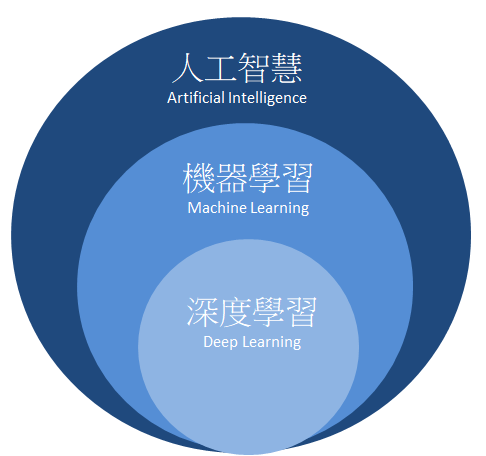
人工智慧是最大的集合,機器學習只是人工智慧的一個獨立分支,他是關於開發具有自我學習能力的演算法,也是這次課程我們主要關注的部分,
深度學習是現在很紅的應用項目,我們這堂課也會提到一些基礎的部分,更深入的進階內容就期待以後有機會開課分享。
人工神經元 (artificial neuron) 的定義是參考人類的神經元給定的,我們下面來看看定義。
/images/Blausen_0657_MultipolarNeuron.png)
假設 $\phi$ 是一個人工神經元函數, $\phi$ 的輸入就是一串訊號 $(x_1, \cdots , x_n)$ , $\phi$ 的第一步會把訊號做加權,
\[z= w_1 x_1 + \cdots + w_n x_n\]我們腦中也常常會自動忽略我們不在意的訊號(例如你老闆的叫聲),也會自動加強你在意的訊號(例如你男女朋友的呼喚)。
第二步就是根據這些訊號,我們決定要不要被激活,如果 $z$ 大於例如 $0.5$ 就被激活,小於 $0.5$ 就不被激活,這其實就叫做邏輯回歸 (logistic regression) 我們以後會提到。
深度學習就是把很多神經元疊加起來去做分析判斷的技術。
機器學習
我們先來看看幾種類型的機器學習:
- 監督學習 (supervised learning)
- 非監督學習 (unsupervised learning)
- 強化學習 (reinforcement learning)
- 半監督學習 (semi-supervised learning)
- 自監督學習 (self-supervised learning)
Supervised Learning (監督學習)
定義
所有的資料(訓練資料,驗證資料,測試資料)都被「標註」 (label),告訴模型相對應的值,以提供機器學習在訓練模型,驗證模型時判斷預測與標註的差異。
更多的碎碎念
你知道機器學習 (Machine Learning) 可以分為幾類嗎?根據資料被標記的狀態可以分為下面幾種
- 監督式學習 (Supervised Learning)
監督學習通常分為分類與回歸兩類問題,我們之後要講的好用工具 scikit-learn 常見算法有決策樹(Decision Tree, DT)、支持向量機(Support Vector Machine, SVM)和神經網絡等。 - 非監督式學習 (Unsupervised Learing)
- 增強式學習 (Reinforcement Learning)
我們在以後還會看到更多分類,例如自監督學習(Self-Supervised Learning)參考範例
/images/SupervisedLearningModelWhite.png)
/images/UnsupervisedLearningModelWhite.png)
我們下面來說點人話
什麼是監督學習啊,其實就是填鴨式教育,假設我們要讓電腦學會判斷貓跟狗。
我們要準備很多貓貓跟狗狗的圖片,並且跟電腦說這張圖片是貓貓,那張圖片是狗狗。 所以監督學習的重點是要電腦學會什麼?
沒錯就是預測,這個例子是要學會預測貓狗,或是延伸到預測股票的漲跌等等。
Scikit Learn
scikit learn 是現在最流行的機器學習套件之一, scikit learn 是基於 SciPy, Numpy 等 python套件建構的用於機器學習的 Python 套件。
下面一張圖是 scikit learn 作弊小抄。
/images/ml_map.png)
我們之前已經介紹機器學習的大致任務分類,Supervised Learning 監督學習,Unsupervised Learning 非監督學習。
那在 scikit learn 裡面可以分為四大項目 classification 分類,clustering 聚類,regression 迴歸,dimensionality reduction 降維。
這邊有兩個名詞 classification 分類,clustering 聚類 有人知道其中的差別嗎?
下面就來解說一下這四大類。
- Classification:
如果我們的訓練資料有標記要拿來分類,則這種任務就是 Classification 。 - Clustering:
如果我們的訓練資料有一堆,但是沒標記,要做的是unsupervised learning,做聚類分堆問題,則這種任務就是 Clustering 。 - Regression:
如果要做的分類不是離散,是連續的,例如要預測股價,房價等等,這種任務就是Regression。 - Dimensionality reduction:
如果資料的維度太多,可以利用 scikit learn 裡面的方法來降維,例如 PCA 。
基本流程
我們下面來談談機器學習的訓練流程,下面的流程是監督學習的流程,監督學習的學習方法跟我們在補習班學習的填鴨式教育非常相像。
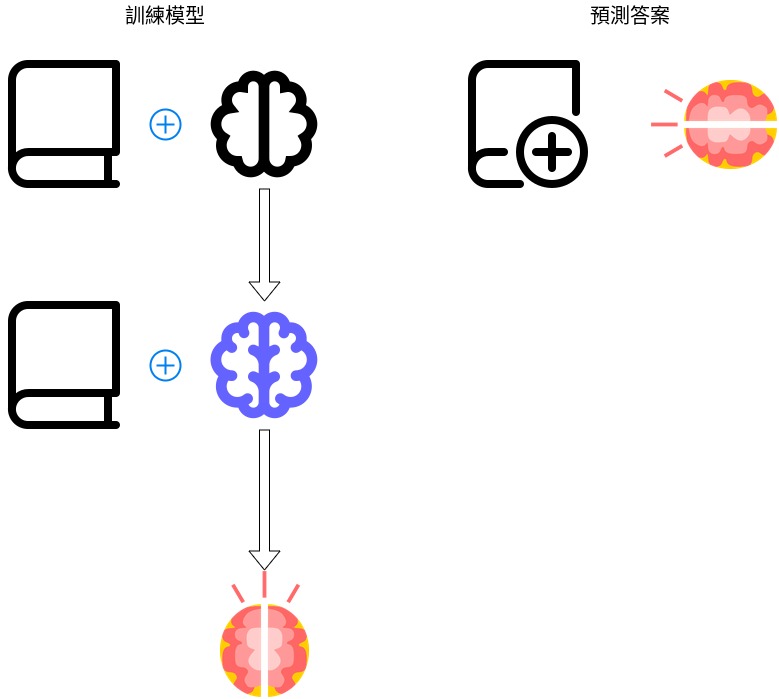
Baseline Model
基本模型就是最基本的模型,可以是平均或是固定值。 為什麼我們要有 Baseline Model?
